

先附上源代码:
import requests
import re
import time
import random
search=str(input("search syntax:"))
page1=int(input("start-page:"))
page2=int(input("end-page:"))
path=str(input("path:"))
try:
i=page1
for i in range(page1,page2+1):
print("page:"+str(i))
derpy="derpicdn.net"
search_url="https://trixiebooru.org/search?sd=desc&sf=score&page="+str(i)+"&q="+search
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0",
"cookie":"filter_id=100073"
}
results1=requests.get(url=search_url,headers=headers)
pattern1=re.compile(r'https://[^\s<>"]+[^\s<>"]')
s1=pattern1.findall(results1.text)
targets1 = []
id = []
date_id = []
targets2 = []
type = []
for i in range(0,len(s1)):
index1=s1[i].find(derpy)
if index1!=-1:
#print(s1[i][-9:-4])
if s1[i][-2:]!=";}" and s1[i][-2:]!=";]":
print(s1[i])
targets1.append(s1[i])
type.append(s1[i][-3:])
for target in targets1:
match1=re.search(r"img(.*)/t",target)
if match1:
original_number=match1.group()
num1=original_number.replace("/t","")
num2=num1.replace("img","")
#print(num2)
date_id.append(num2)
match2=re.search(r'\/([^\/]+)$',num2)
id.append(match2.group(1))
#print(len(id))
#print(len(date_id))
original_url="https://trixiebooru.org/images/"
for j in range(0,len(id)):
url1=original_url+id[j]
key=id[j]+"__"
results2=requests.get(url=url1, headers=headers)
if type[j]=="gif":
pattern2=re.compile(key + r"(.*?)\.gif")
s2=pattern2.findall(results2.text)
#print("s:"+str(len(s2)))
if len(s2)==2:
s=s2[0]+"."+type[j]
#print(s)
target_url="https://derpicdn.net/img/view"+date_id[j]+s
targets2.append(target_url)
print("正在获取第"+str(j+1)+"个目标...")
i+=1
if type[j]=="png":
pattern3=re.compile(key + r"(.*?)\.png")
s3=pattern3.findall(results2.text)
#print("s:"+str(len(s3)))
if len(s3)==2:
s=s3[0]+"."+type[j]
#print(s)
target_url="https://derpicdn.net/img/view"+date_id[j]+s
targets2.append(target_url)
print("正在获取第"+str(j+1)+"个目标...")
i+=1
if type[j]=="jpg":
pattern4=re.compile(key + r"(.*?)\.jpg")
s4=pattern4.findall(results2.text)
#print("s:"+str(len(s4)))
if len(s4)==2:
s=s4[0]+"."+type[j]
#print(s)
target_url="https://derpicdn.net/img/view"+date_id[j]+s
targets2.append(target_url)
print("正在获取第"+str(j+1)+"个目标...")
i+=1
for target in targets2:
print("target:"+target)
print("downloading...")
n1=random.randint(10000,99999)
n2=random.randint(10000,99999)
test=requests.get(url=target,headers=headers)
pictrue=str(n1)+str(n2)+"."+target[-3:]
with open(path+"\\"+pictrue,"wb") as t:
t.write(test.content)
print("Done!")
time.sleep(1)
except:
print("download error!")
#default:100073
#everything:56027此脚本需要本地搭建python环境,复制源代码到文件,改后缀为py。

脚本会要求输入呆站搜索语句、抓取图片的起始页和结束页以及图片保存的路径。以artist:magnaluna为例
运行截图:
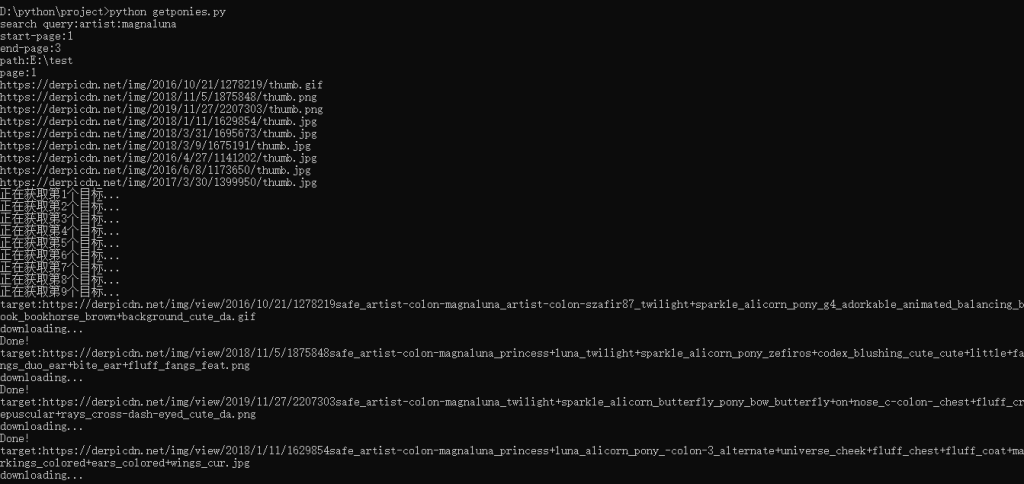
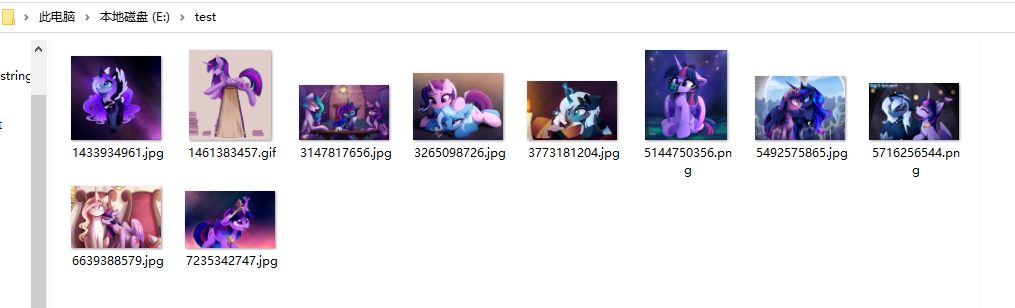
稍等片刻就可以在对应文件夹下看到小马啦!
#脚本使用的过滤器默认为default,如果需要更换的话可以自行更改源码headers里面的filter_id
100027:Default
56027:Everything
37431:Legcy Default
37429:18+ Dark
37432::18+ R34
37430:Maximum Spoilers
在下学艺不精,还请大佬们多多包含!


